异常和集合
异常
throw
异常就是当程序执行到一段代码,发生异常后,就new一个对应的类的对象,这个类是一个异常类,如:NullPointerException和NumberFormatException,然后throw或者catch,throw就是抛出一个异常,和return对比。
| throw | return |
|---|---|
| 异常退出 | 正常退出 |
| throw后执行的代码不定,看异常处理机制动态决定 | 返回位置确定:上一级调用者 |
try/catch
1 | System.out.println("请输入一个数字"); |
如果在try内跑出来异常,可以由catch来捕获,捕获后程序还会继续运行而不会退出,只是try后续的代码不会执行。
异常类体系(记下来)
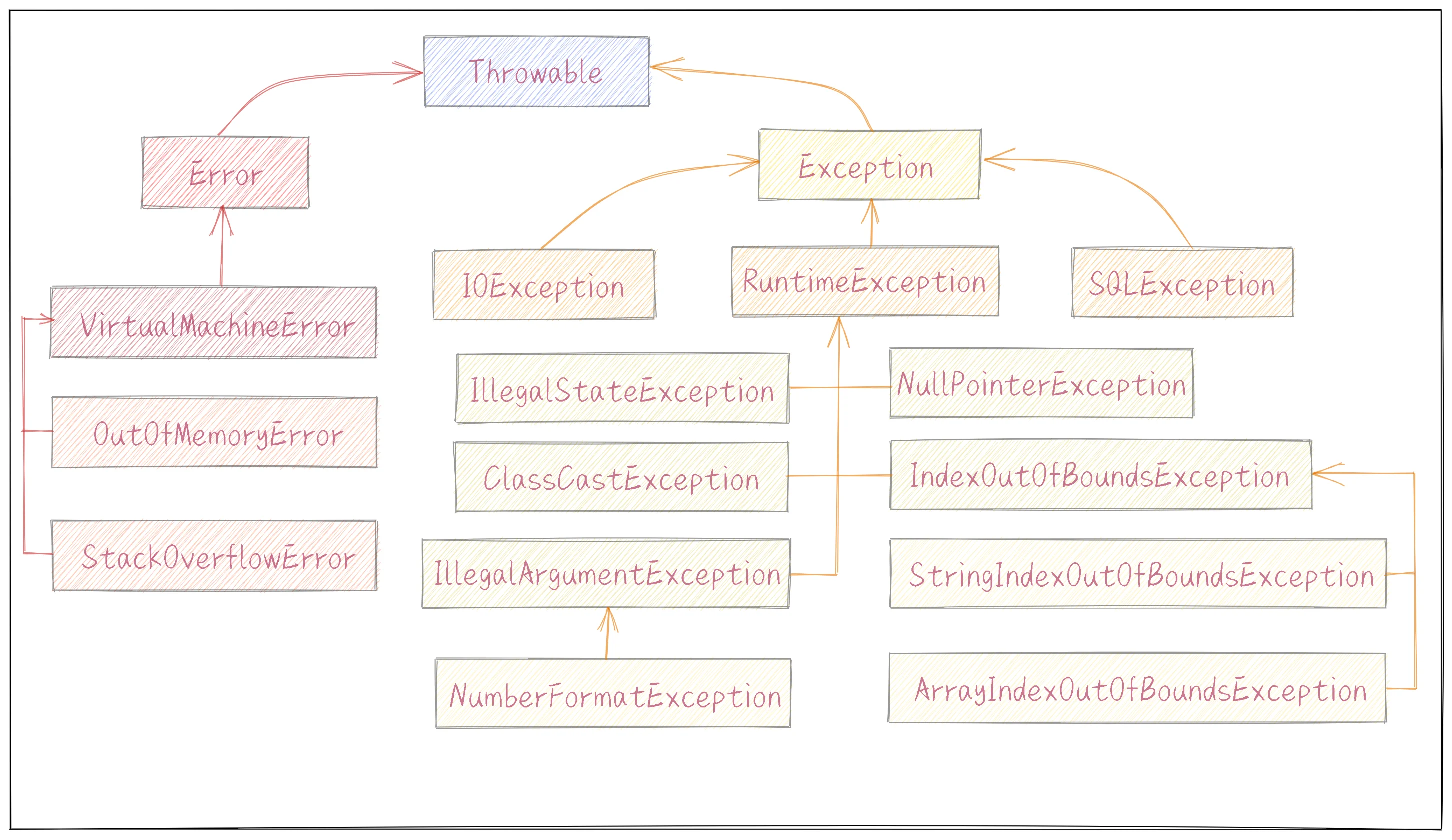
Throwable是所有异常类的基类,他有两个子类Error和Exception。
Error表示系统错误或资源耗尽,应用程序不抛出或处理,虚拟机错误及其子类,内存溢出错误和栈溢出错误。Error及子类都是未受检异常。
Exception中有很多子类,也可以继承Exception自定义异常,其中列出来数据库异常,IO异常,和运行时异常(未受检异常)受检异常不能通过编译。
| 异常 | 说明 |
|---|---|
NullPointerException |
空指针异常 |
IllegalStateException |
非法状态 |
ClassCastException |
非法强制类型转换 |
IllegalArgumentException |
参数错误 |
| 异常 | 说明 |
|---|---|
NumberFormatException |
数字格式错误 |
IndexOutOfBoundsException |
索引越界 |
ArrayIndexOutOfBoundsException |
数组索引越界 |
StringIndexOutOfBoundsException |
字符串索引越界 |
这些异常大部分只是定义了几个父类的构造函数。
自定义异常
然后自定义异常继承的RuntimeException或他的某个子类,则自定义异常也是未受检异常;如果继承的是Exception和Exception其他子类,则自定义异常是受检异常。
1 | public class AppException extends Exception { |
异常处理
异常处理包括catch、throw、finally、try-with-resources和throws
catch匹配
1 | try{ |
上方异常要是下方异常的子类,java7开始支持一种新语法
1 | try{ |
throw和finally
处理完异常之后,可以通过throw抛出异常给上一层,可以是原来的异常,也可以是新异常。
finally内代码,无论有无异常发生都会执行。
如果没有异常发生,try执行后执行finally
如果有异常被catch,catch执行后执行finally
如果有异常发生但没被catch,在异常被抛出前执行finally
注意:如果try或catch中有return时,也会先执行完finally中的代码再去执行return;如果finally内有return或抛出异常,则会覆盖掉catch和try中的return和异常。
try-with-resources
finally一般用于释放资源,java7之前要实现AutoCloseable接口之后,在finally中调用close()方法,代码如
1 | public interface AutoCloseable { |
java7支持了一种新语法,在执行完try语句之后自动执行close()方法。
1 | public static void useResource() throws Exception { |
throws
throws跟在方法后面,可以声明多个异常,以逗号分隔。表示:这个方法可能会抛出这些异常,且没有处理或者没有处理完,调用者必须进行处理。
集合
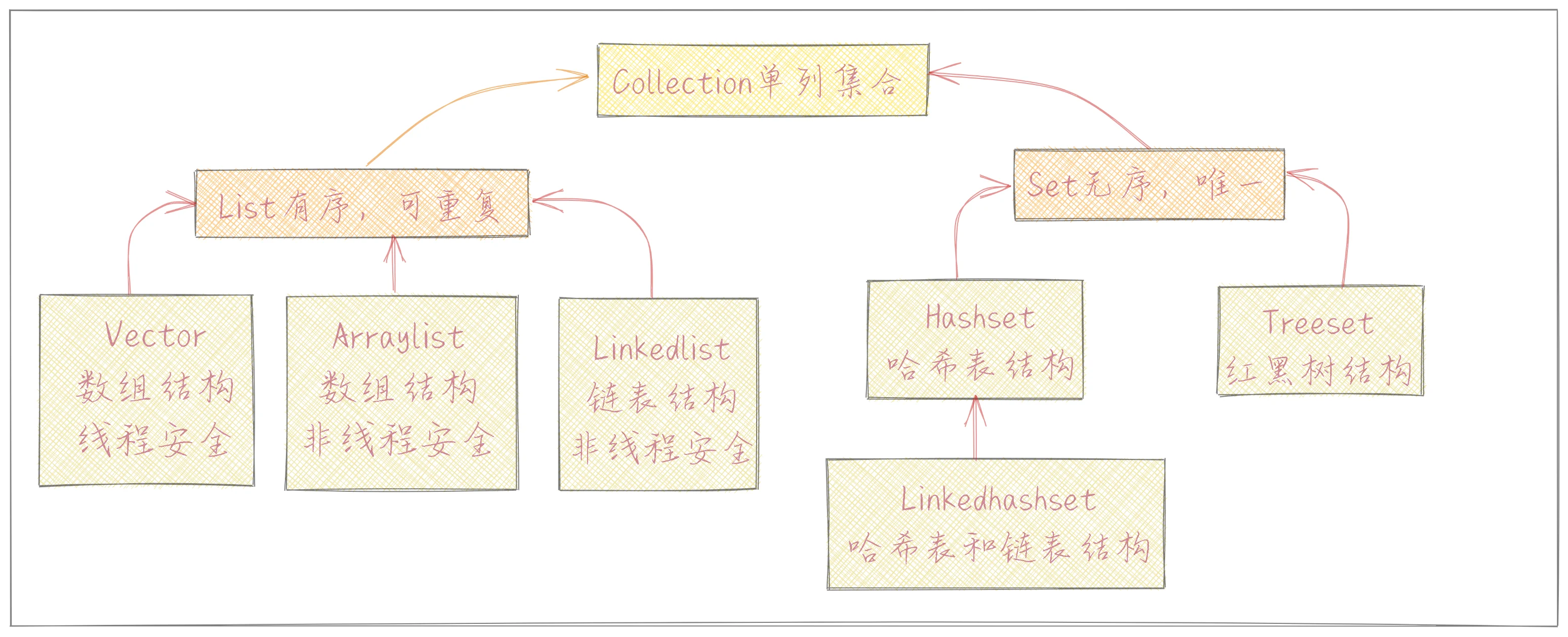
Collection
1 | //添加 |
List
存取有序,有索引,元素可重复
ArrayList(增删慢,改查快)
底层是数组
默认参数化容量是10,每次扩容为原先容量的1.5倍
增删时,用数组拷贝复制
删除元素时不会减少容量,若希望减少容量则调用trimToSize()
Linkedlist(改查慢,增删快)
底层是双向链表【双向列表便于实现往前遍历】
Vector
底层是数组,基本被ArrayList代替,原因如下:
所有方法都是同步的,有性能损失。
初始长度是10,超过后以100%增长,相比ArrayList更消耗内存
对比
ArrayList的增删慢并不是绝对的
如果增加的一直是add()增加到末尾的话
一直删除末尾的元素
如果删除中间位置的元素,还是ArrayList快
但是一般来说:增删多还是用LinkedList
Set
存取无序,元素不可重复,set也是Collection的子接口
可以使用迭代器
可以使用增强for
不能使用索引
HashSet(数组+链表+红黑树)
原则参考HashMap
实现了Set接口
实际上是HashMap
可以存放一个null
不能重复,存取无序
LinkedHashSet
LinkedHashSet继承了HashSet,底层是一个LinkedHashMap,底层维护了一个双向链表。每一个节点都有before和after属性,添加元素的原则和hashset一样
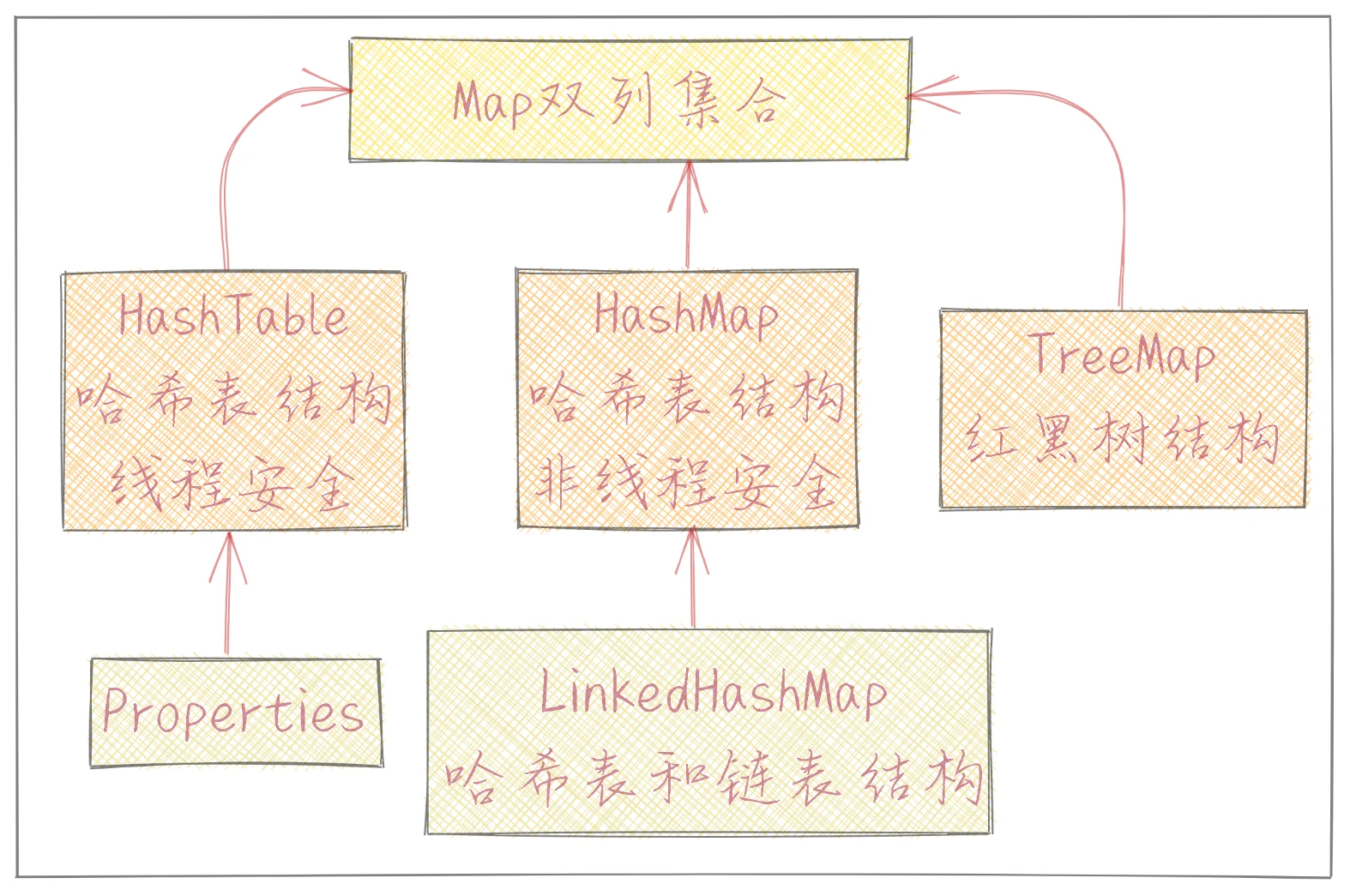
Map
map和collection并列,用于保存有映射关系的数据:ket-value
key和value可以是任何引用类型的数据,会被封装到HashMap$Node对象中
key值不可以重复,value可以重复
key值只能有一个null,value可以有多个null
常用String类作为Map的key
添加相同的key,相当于修改value
Map的遍历
1.通过set取出所有的key,然后通过for进行遍历
1 | Set keyset = map.Keyset(); |
2.迭代器
1 | Iterator iterator = keyset.iterator(); |
3.4.同1、2取出value
5.通过EntrySet
1 | Set entryset = map.entrySet(); |
HashMap(数组+链表+红黑树)
数组用来存储元素数据,链表解决冲突,红黑树提高查询效率。
如果链表长度>8&数组大小≥64,链表转为红黑树
红黑树节点数<6,转为链表
put的过程:

哈希值为32位int类型,计算的新哈希值是16高位和16低位异或,然后对数组长度(初始16)取模,取模的方法是和15进行&操作,直接保留后几位二进制数。
如果传入的不是2 的整数次方时,则向上找到2的整数次方大小,比如传入17是应该找到32。
哈希函数的构造方法:除留取余法、直接定址法、数字分析法、平方取中法、折叠法
扩容要rehash,十分耗时,为什么扩容因子取0.75?如果取得比较大,元素很多空位很少才扩容,那么发生哈希冲突的概率就增大了,查找的时间成本增加。如果设置比较小,查找时间成本降低,但是需要更多的空间,空间成本增加了。
HashTable
hashtable和hashmap的使用方法基本一样,他是线程安全的,但键和值都不能为null
| 线程安全 | 效率 | 运行null键null值 | |
|---|---|---|---|
| HashMap | 不安全 | 高 | 可以 |
| Hashtable | 安全 | 较低 | 不可以 |
Properties
使用特点和Hashtable类似,properties还可以用于从xxx.properties文件中加载数据到properties对象进行读取和修改,xxx.properties文件通常作为配置文件
总结
1.先判断存储的类型(单列或双列)
2.单列:collection接口
允许重复:List
增删多:LinkedList
改查多:ArrayList
不允许重复:Set
无序:hashset
排序:TreeSet
插入和取出顺序一致:LinkedHashSet
3.双列:Map
键无序:HashMap
键排序:TreeMap
键插入和取出顺序一致:LinkedHashMap
读取文件Properties